
Understanding How the RK1820 Co-Processor Collaborates with the RK3588
Why is there increasing talk about NPUs and co-processors in edge devices? While the RK3588 is a powerful SoC with 6 TOPS (INT8) of compute, single-chip capabilities inevitably hit limits in complex scenarios like multi-task inference, model parallelism, and video AI analysis. The RK1820 was introduced precisely to handle the workload that causes “compute anxiety” for the main SoC.
In endpoint AI devices, the main SoC no longer “fights alone.” As AI tasks begin to exceed the scheduling capabilities of traditional CPUs/NPUs, co-processors are quietly taking over part of the intelligent workload.
Co-Processor RK1820
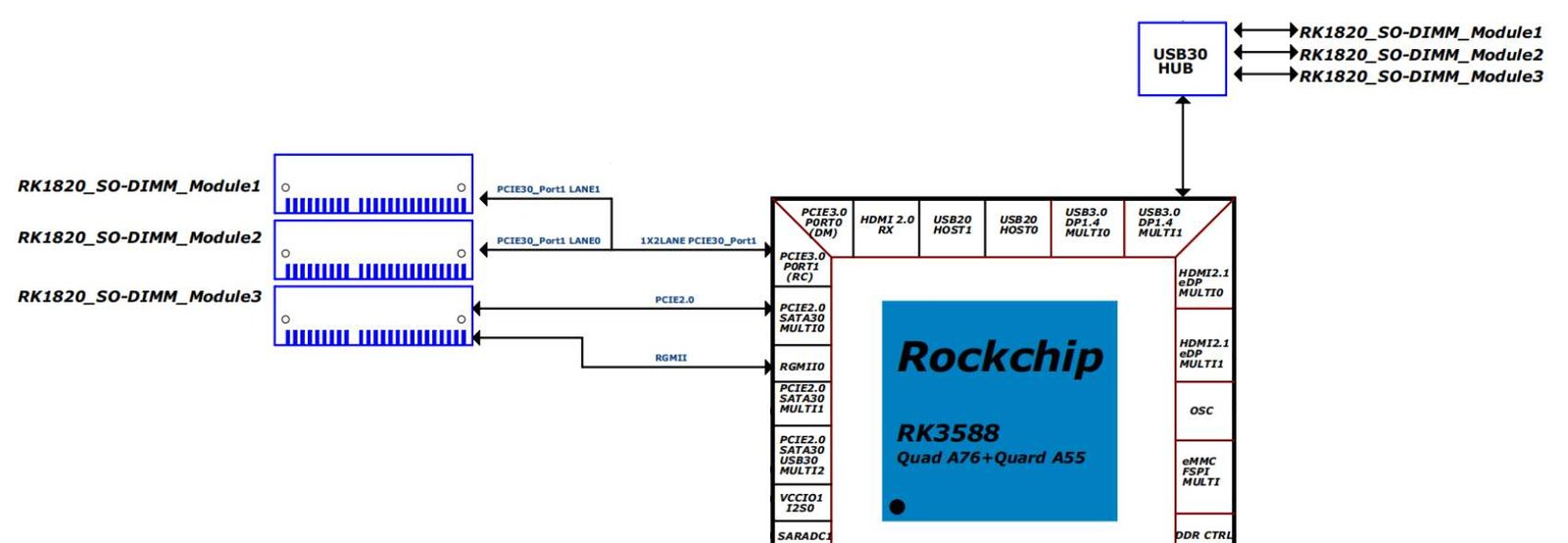
The RK1820 is a co-processing chip specifically designed for AI inference and compute expansion. It can be flexibly paired with host SoCs like the RK3588 and RK3576, achieving efficient communication via interfaces like PCIe and USB.
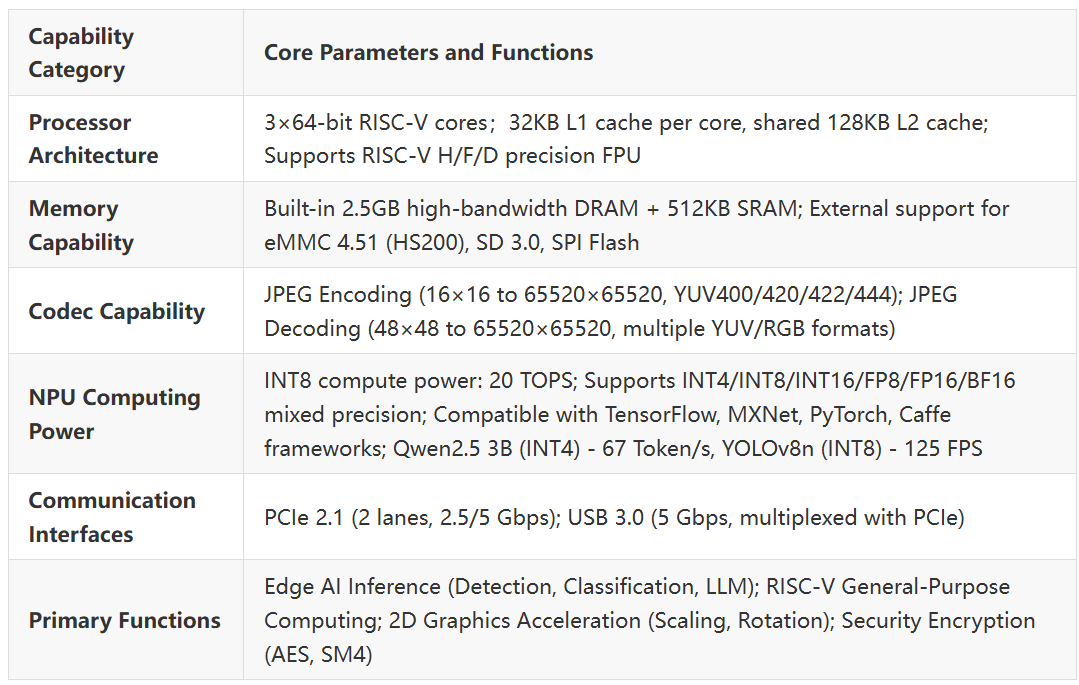
“Who Does What”
See the division of work from a system architecture perspective.
In an RK3588 + RK1820 system, the AI task processing pipeline can be broken down into a four-layer architecture:
Application Layer → Middleware Layer → Co-Processing Execution Layer → Control & Display Layer
- RK3588 Host: Responsible for task scheduling, data pre-processing, result output, and end-to-end process management.
- RK1820 Co-Processor: Dedicated to high-compute AI inference. It interfaces with the host via the PCIe bus, creating a “light control, heavy compute” collaborative model.
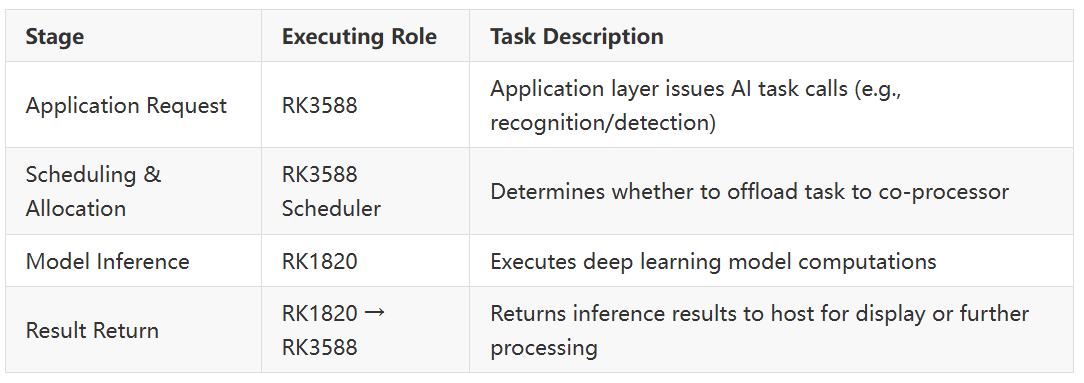
- Application Layer: The “Initiator” of AI Tasks
This layer is the starting point for AI tasks, translating user requirements (e.g., image analysis, object detection, edge LLM Q&A) into executable task commands and passing them to the middleware layer via standardized interfaces. This layer is entirely managed by the RK3588 host, as it handles user interaction, business logic, and peripheral data management.
Task Reception: Acquires user commands via peripherals like cameras, touchscreens, Ethernet, and serial ports. For example,
- Smart Security: Detect people in a video feed.
- Industrial Inspection: Identify surface defects on products.
- Edge LLM: Convert voice input to text to form a Q&A task.
Command Standardization: Converts unstructured inputs into structured task parameters.For example,
- Image Tasks: Input resolution, model version, output requirements.
- LLM Tasks: Input tokens, model version, output length limits.
- Middleware Layer: The “Dispatcher” of AI Tasks
The middleware layer is the core hub for collaboration, responsible for task judgment, resource allocation, data pre-processing, and bus communication management. It decides which tasks are executed by the host and which are offloaded to the co-processor.
While the RK3588 host manages PCIe configuration and bus interrupts, the RK1820’s role is focused exclusively on executing the inference tasks it receives.
Task Classification & Scheduling
- Local Processing: Low-compute or high-real-time tasks (e.g., image scaling, lightweight AI inference) are handled by the RK3588’s CPU/NPU/RGA.
- Offload to RK1820: High-compute tasks (e.g., YOLOv8 multi-class detection, LLM inference, semantic segmentation) are handed off to the RK1820. Once the RK1820 takes over, the host CPU/NPU resources are freed up for other task.
Data Pre-processing
- Image Types: Cropping, denoising, normalization, channel reordering.
- Text Types: Tokenization, padding, encoding.
Bus Communication Management
- Establishes communication links via PCIe or USB3.
- Uses DMA for data transfer, requiring no CPU intervention.
- Sends inference control commands, such as starting the NPU, setting precision, and completion interrupts.
- Co-Processing Execution Layer: The “Computer” for AI Tasks
This layer is the core of inference, led by the RK1820 co-processor, which focuses solely on high-compute AI inference.
The RK1820 participates here; the RK3588 does not intervene in the inference process, merely waiting for the results. Timeouts or exceptions can be handled by the RK3588 sending a reset command via PCIe.
Task Reception & Preparation
Receives data, model weights, and instructions dispatched by the RK3588; Writes them to local high-bandwidth DRAM; And loads the model and configures the NPU.
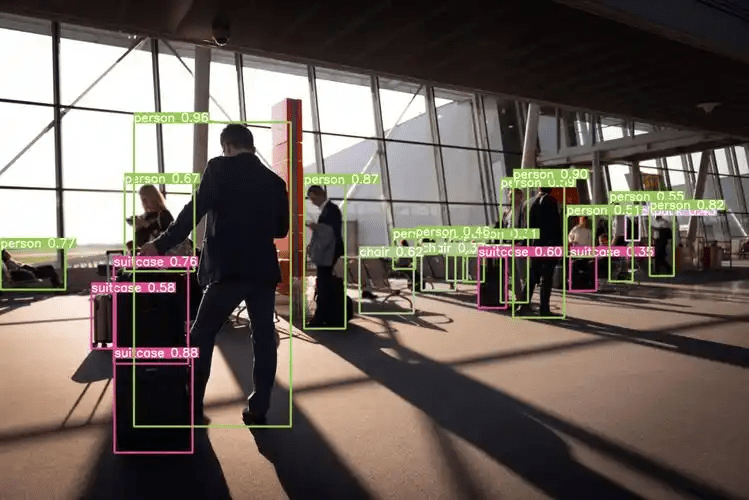
NPU Inference Computation
- Object Detection (YOLOv8n): Convolution → BN → Activation → Pooling → Post-processing NMS.
- LLM Inference (Qwen2.5 3B): Prefill stage processes input tokens → Decode stage generates output tokens sequentially.
- Inference Optimization: Operator fusion, weight compression.
Result Return
- Returns object detection coordinates, class IDs, and confidence scores.
- Returns LLM token arrays.
- Control & Display Layer: The “Output” for AI Tasks
This layer is the endpoint of the AI task, converting the RK1820’s raw inference results into visual or actionable business outputs, completing the loop.
The RK3588 participates here; the RK1820 only outputs raw inference results.
Result Post-processing
- Mapping coordinates back to the original image dimensions.
- Decoding tokens into natural language.
- Counting the number of defects in industrial inspection.
System Control & Feedback Output
- Smart Security: Displaying video with bounding boxes, triggering alarms.
- Industrial Inspection: Controlling the conveyor belt to reject faulty products.
- Edge LLM: Text display + voice broadcast.
Not Just Faster, but Smarter

In simple terms: the RK3588 is responsible for overall coordination and process control, while the RK1820 focuses on computational power. Working together, they make edge AI devices “smarter, faster, and more efficient.”